一、研究背景
近期,将计算机视觉与语言知识融合的进步,使研究人员能够利用上下文语义,给智能机器人建模人类式的常识性知识。机器人视觉和自然语言处理的研究给了机器人有力的工具,让机器人能更好地理解人的行为并帮助人类。
但是机器人在两个方面具有挑战:
- 从对生活中知识的建模与学习中,解释视觉的输入和加强交流互动
- 表现出能够考虑周围物理环境和人类动作及意图的智能的行为
因为人类会在连续的动作中表达意图,理解上下文语义对机器人来说非常重要
如 倒水操作任务:grasp->pour->release
二、研究问题
对人来说,在场景中注意到的东西和已有的常识可以作为前置的知识。智能机器人为了确认未来的执行动作,需要从上下文知识里实时地进行推断。因此,实现一种技术去语义地处理视觉信息并且翻译为操作行为是非常关键的。

三、创新
这篇文章提出了一种方案,用注意力机制基础上的视觉语言模型和本体系统,让机器人理解并转化随时间变化的场景中动态的知识和常识知识。目的是展示预期的操作程序的演变过程,并生成可用于机器人操作决策的视觉注意力轨迹和动态知识图谱。
论文提出:
- 操作概念纳入一个时间不变的知识领域,构建一个本体系统,以树状结构存储对象和关系,作为特定操作任务的常识知识。
*本体:具有上下文结构 - 收集一组由机器人和人类执行的操作任务的RGB-D视频基准数据集,手动为视频帧标注了物体和动作信息的真值。
- 提出了一种基于Seq2Seq的视觉语言模型,并采用空间注意力机制来为视频流中的操作知识进行描述。
- 我们将视觉-语言模型与本体系统相结合,使模型能够语义地解释操作任务的演变,并将其转化为充满常识知识的动态知识图谱。
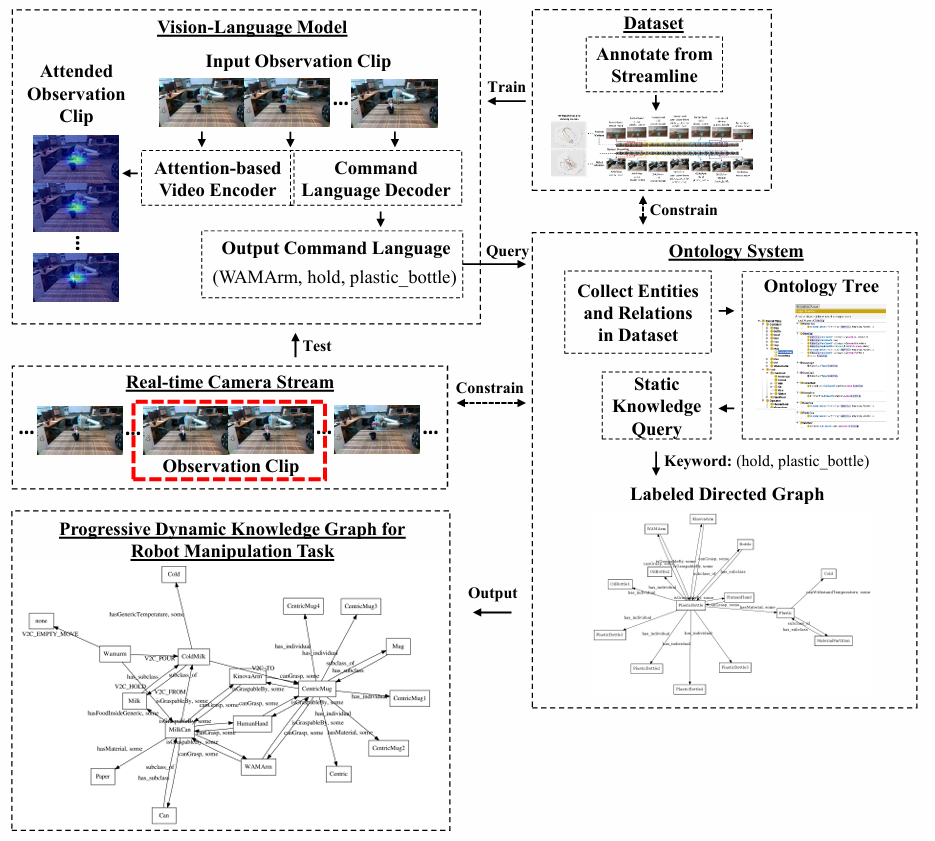
四、方案
相关工作:
以往有许多研究尝试将语言与视觉相结合,但有以下问题:
- 对少量固定帧进行采样,在实时视频流中需要持续反馈时并不合适
- 过度依赖于物体检测,与操作上下文的联系较弱
1.流取样
定义相机流为观察到的机器人一系列动作的场景,从时刻T0到无穷 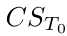
图像帧为 I
视频为不同时间图像帧的集合,每个视频表示一个任务的阐述 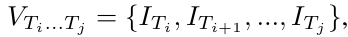
数据集为不同时间视频的集合 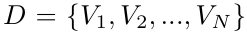
假设我们的图像没有长期时间依赖性,即一个观察在一个时间窗口内是”最相关和可信的”,我们进一步定义这个中间观察为一个长度为L的小片段 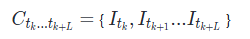
我们的目的是在图像流持续进入观察窗口过程中,始终维护一个最大长度L的队列作为观察窗口
当满足以下条件之一时,会收集一个片段:
(1)观察窗口第一次被填满;(2)观察窗口中L/2的帧被替换为新的图像。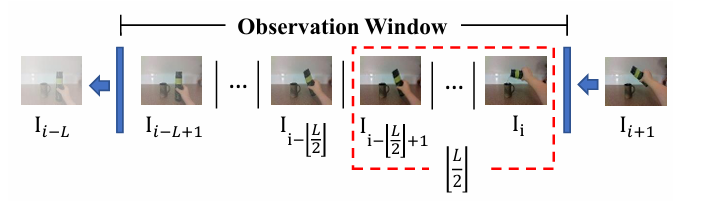
2.机器人语义数据集
我们使用英特尔RealSense D435i摄像头收集了一系列操作任务的720p视频,每个视频展示了一个完整的特定操作任务,数据集中包含两种类型的操纵器:人类实验对象和Barrett全臂操纵器(WAM)机器人。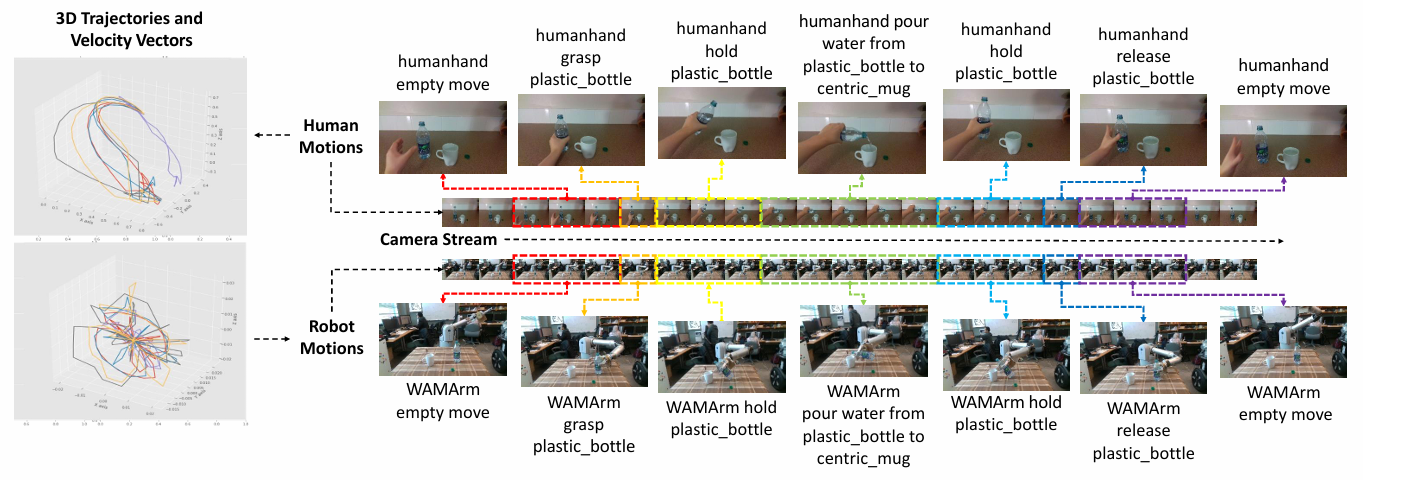
3.操作领域知识本体
我们构建了一个本体系统,用于存储和查询关于操作概念的明确定义的常识性知识。
给定一组语义实体,包括数据集中的操纵对象和操纵器
对于任意两个语义实体,我们施加一组二进制逻辑约束LC到一个分类和关系结构中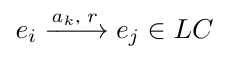
关系集合 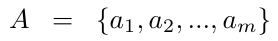
r表示限制(数量、基数、权值)
E + A,实体+关系 代表整个操作领域知识的完整语义词汇。
4.定义动态知识
为了随时间解释场景中视觉数据中的操作知识,我们使用一个动态知识图谱,其中包含时间属性
定义动态知识图谱为一个带标签的有向图 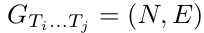
其中的边由二进制逻辑限制LC组成,图中的任何边e属于E,跨度为LC,任何节点n属于N,跨度为E + A。节点可以在空间上连接。此外,还应用了与视觉数据相对应的时间约束。
对于任何时间段Ti…Tj内的视觉数据,包括片段、视频和数据流,动态知识图谱描述了在该时间段内呈现的一组关系。
定义指令语言S,作为动态知识图谱的基本框架 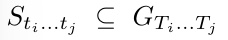
用指令语言S描述操作动作中最重要的关系组合,它具有长度L,表示为: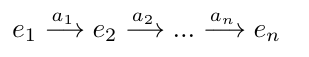
对于命令语言中感知到的任何实体ei,,实体中的常识可以从本体系统被列入带标签的有向图中 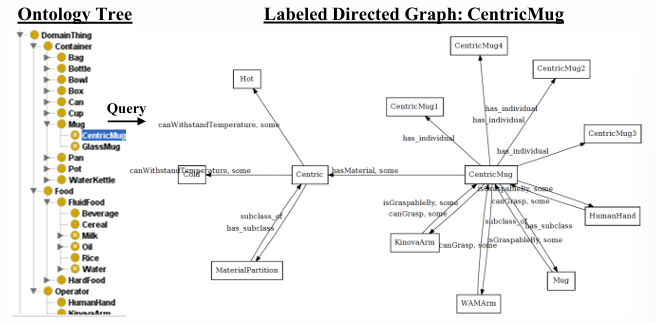
动态知识图谱可以被看作指令语言和所有带标签有向图的并集 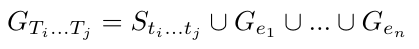
5.结合视觉和语言
给定一个观察片段 C 作为输入,我们的目标是生成一个指令语言,并获取该时间段内t1到tL的相关视觉注意力。
我们提出使用基于注意力的Seq2Seq模型,这种方法可以从观察片段中自动推断出描述操作过程的指令语言,并通过注意力机制关注相关的视觉区域,从而实现对视觉数据中操作知识的表示和理解。
空间注意力:
通过分配的语义标签,这种隐式学习的注意力机制能自适应地关注视频片段 N 帧中相关的显著区域。
时间t处的向量Zt是图像特征 ati (大小为 L×H×W) 中相关显著部分的动态表示。生成一个正标量权重 αti ,用于解释位置 i 的相对重要性。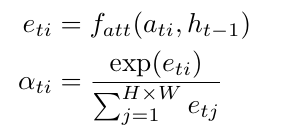
注意力加权的视觉特征 zt 通过加权求和的方式得到: 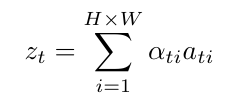
使用Seq2Seq生成指令语言:
长短期记忆网络(LSTM)是一种递归神经网络,它能从输入数据中学习到长期依赖关系。
给定时间t下,注意力加权的视觉特征输入zt,隐藏层ht和记忆细胞层ct被计算为:
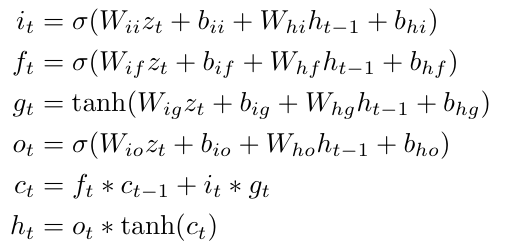
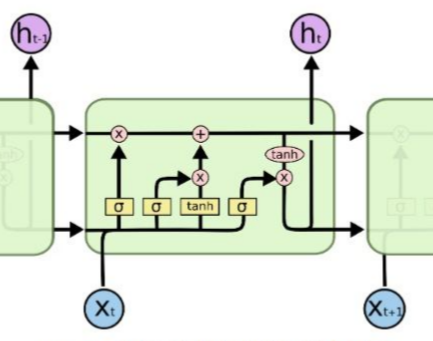

Seq2Seq模型是一种编码-解码结构。通过编码LSTM学习获得编码向量v,通过解码LSTM学习基于编码向量生成目标指令序列s1…,sK
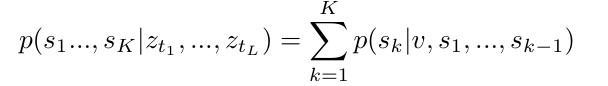
通过最大化对数似然目标函数进行优化训练,可以最大化生成正确命令序列的概率。
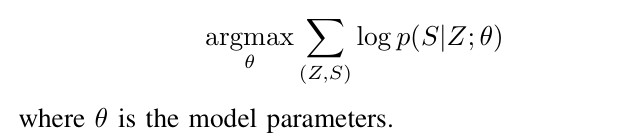
五、总结
在这篇论文中,我们提出了一种方案,将含有常识性知识的视觉注意力和演化的动态知识图谱结合起来,该方案融合了视觉-语言模型和本体系统,可以处理实时摄像头数据流。总的来说,我们未来的研究将聚焦于将操纵环境与智能机器人动作控制器相结合。